1. 데이터 증강(Data Augmentation)데이터 증강은 머신러닝 모델을 학습할 때 사용되는 데이터의 양과 다양성을 인위적으로 증가시키는 방법입니다. 주로 이미지, 텍스트, 시계열 데이터 등 다양한 유형의 데이터에 적용할 수 있으며, 모델이 더 일반화된 특성을 학습하도록 도와줍니다. 데이터 증강은 특히 데이터의 불균형 문제를 해결하고, 과적합을 방지하는 데 유용합니다.데이터 유형별 데이터 증강 방법이미지 데이터회전(Rotation): 이미지를 일정 각도로 회전시켜 다양한 시점에서의 이미지 특성을 학습하게 합니다.이동(Translation): 이미지를 일정 거리만큼 상하좌우로 이동시킵니다.크기 조절(Scaling): 이미지를 확대하거나 축소하여 다양한 크기의 특성을 학습할 수 있게 합니다.뒤집기(F..
이상탐지 시스템을 구성할 때 정상 데이터만을 사용하여 모델을 학습하는 과정에서는 몇 가지 중요한 사항에 유의해야 합니다. 이는 모델이 정상 데이터를 충분히 학습하여 이상치를 정확하게 탐지할 수 있도록 하기 위해 필요합니다. 말씀하신 것처럼 데이터 분포의 불균형, 시계열 데이터의 연속성 문제 등이 주요한 예시입니다. 아래에서는 다섯 가지 알고리즘(VAE, Isolation Forest, One-Class SVM, LSTM, Transformer)을 통해 이러한 문제를 어떻게 다룰 수 있는지 상세히 설명하겠습니다.1. 데이터 분포의 불균형 문제문제 정의:특정 분야의 데이터가 원래의 데이터 분포에서 너무 적게 발생하거나 특정 클래스가 과도하게 나타나는 경우, 모델이 정상 분포를 제대로 학습하지 못해 이상 탐지..
최근 비지도 학습 기반의 이상탐지 모델에서는 LSTM(Long Short-Term Memory), Transformer 등의 딥러닝 알고리즘이 활발하게 사용되고 있습니다. 이러한 알고리즘들은 특히 복잡한 시계열 데이터, 텍스트, 그리고 이미지에서 유의미한 이상 패턴을 감지하는 데 적합합니다. 아래에서 각 알고리즘의 사용 사례, 데이터 특성, 이상 여부 평가 방법, 장점과 단점, 주의 사항 등을 상세히 설명하겠습니다.1. LSTM(Long Short-Term Memory) 기반 이상탐지1) 사용 분야시계열 데이터: 금융 거래 데이터(이상 거래 탐지), 네트워크 트래픽(사이버 보안), 제조 공정 데이터(장비 고장 예측) 등에서 사용됩니다.의료 데이터: 심전도(ECG)나 혈당 수치 등의 생체 신호에서 비정상 ..
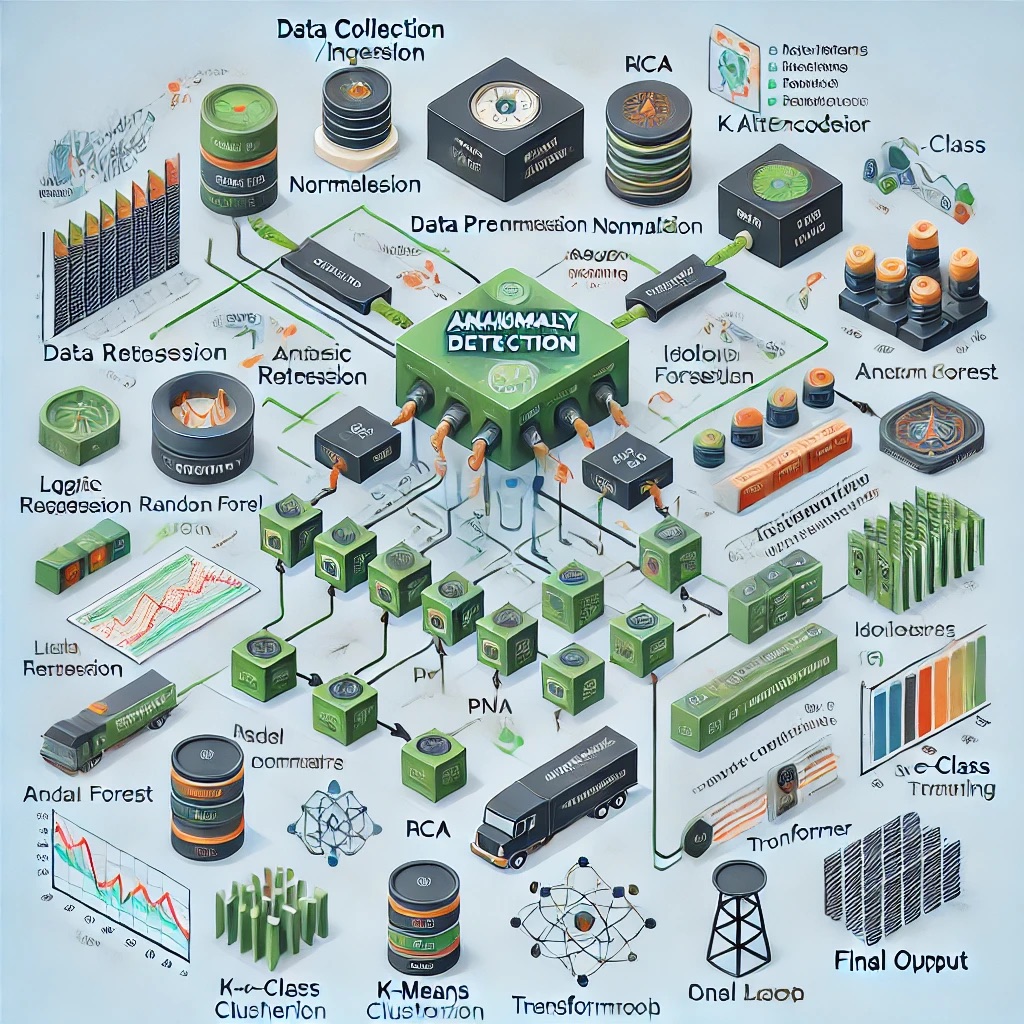
이상탐지(Anomaly Detection)는 정상적인 패턴에서 벗어난 데이터를 식별하는 작업으로, 여러 분야에서 중요한 역할을 합니다. 이상탐지 모델은 크게 지도학습(Supervised Learning) 기반과 비지도학습(Unsupervised Learning) 기반으로 나눌 수 있습니다. 각각의 대표적인 알고리즘을 소개하겠습니다.1. 지도학습 기반 이상탐지 모델지도학습 기반 모델은 정상 데이터와 이상 데이터를 구분할 수 있는 레이블이 주어진 경우에 사용됩니다. 주어진 데이터셋을 학습하여 새로 들어온 데이터가 정상인지 이상인지 분류합니다. 대표적인 알고리즘으로는 다음과 같은 것들이 있습니다:이진 분류(Binary Classification) 모델: 로지스틱 회귀(Logistic Regression): 기..